Prob: What are the two equivalent definitions of events A and B being independent?
P(A,B) = P(A)P(B)
OR
P(A) = P(A | B=b) for all values of b
(Pretty darn sure second is correct)
Prob: Conceptually, what does it mean for A and B to be independent events?
A and B are independent events if knowing whether one event happened or not gives you no information on whether the other happened.
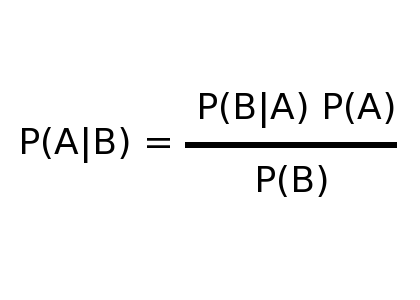
Prob: What is Bayes’ Theorem?
Prob: What is the formula for the expected value of discrete RV X?
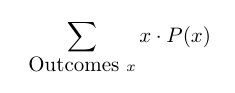
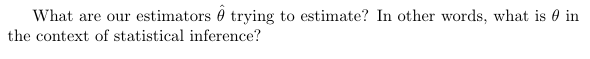

Stat: What is the formula for MSE(Ø_h), or Mean Squared Error?
MSE(Ø_h) = E[(Ø_h - Ø)2 ]
= V(Ø_h) + bias(Ø_h)2
but only really need that first part
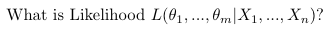
It describes how likely those a distribution with those parameters was to make that dataset.
(I think it is often talked about in the context of a specific family of distributions. So we might say, what is the likelihood of a normal distribution with these paramaters, given this dataset?)
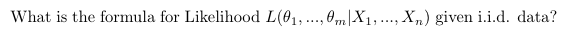
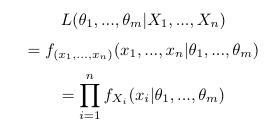
Stat: When we find a Maximum Likelihood Estimator, Min-Var Unbiased Estimator, Method of Moments Estimator, or something similar, do we typically find it in the context of some assumed distribution family (i.e. assume the distribution is normal, exponential, etc), or estimate parameters without a suspected distribution?
While sometimes we estimate parameters without a suspected distribution, such as distribution mean and variance, we generally more often use an assumed distribution family.
(This is mostly my opinion, and also me wanting to remember that when we for example “find the MLE”, it generally has quite a bit of structure due to an assumed distribution that we can differentiate/optimize.)
Stat: What is a Maximum Likelihood Estimator?
It is the estimator Ø_hat of Ø that maximizes the likelihood of your data.
So, generally for some assumed distribution family such as Exponential Distributions, you try to find an estimator lambda_hat for parameter lambda that leads to the exponential distribution that was most likely to produce this data.
Stat: At a high level, how do you find the MLE estimate for the parameters?
Differentiate the likelihood w.r.t. the parameters and set that equal to zero, then solve
Stat: Given observations X1,…,Xn, what is the maximum likelihood estimator for a population proportion: for example, the proportion of red balls if we’re drawing from red, green or blue?
reds/n
Stat: What is the key feature of classical, or frequentist, statistics? And what are some types of analytical tools used in this statistical philosophy?
In classical/frequentist statistics, the parameter Ø is constant. We examine it using estimators Ø_h, we quantify our uncertainty of its value using confidence intervals, and we test theories using hypothesis tests and p-values.
Stat: What is the key feature of bayesian statistics? And what are some types of analytical tools used in this statistical philosophy?
The parameter Ø is viewed as variable, and we quantify our opinions around its potential values using a prob dist π.
Stats: In Bayesian statistics, how do we update π, our prior distribution of Ø, using data Xi?
You incorporate using a method looking very similar to Bayes’ law.
Specifically:
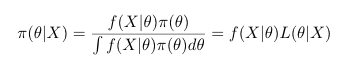
Stats: In bayesian statistics, what happens to the prior distribution as we get more and more data?
With enough data, the impact of the prior distribution on the posterior distribution tends towards 0.
ML: When would you use MAP estimation of a parameter instead of MLE estimation?
MAP allows you to include some prior distribution of the parameter before factoring in the data. So, if you have suspicions about the value of a parameter, perhaps because of domain knowledge, then MAP could be better as it will allow you to encorporate that knowledge.


